深浅模式
SQL
DDL
Data Definition Language,数据定义语言,用来定义数据库对象(数据库,表,字段) 。
- 查询所有数据库
sql
show databases;- 查询当前数据库
sql
select database();- 创建数据库
sql
create database [ if not exists ] 数据库名 [ default charset 字符集 ] [ collate 排序规则 ];- 删除数据库
sql
drop database [ if exists ] 数据库名;- 切换数据库
sql
use 数据库名;- 查询指定表的建表语句
sql
show create table 表名;- 建表语句
sql
CREATE TABLE 表名(
字段1 字段1类型 [COMMENT 字段1注释 ],
字段2 字段2类型 [COMMENT 字段2注释 ],
字段3 字段3类型 [COMMENT 字段3注释 ],
......
字段n 字段n类型 [COMMENT 字段n注释 ]
) [ COMMENT 表注释 ] ;- 添加字段
sql
ALTER TABLE 表名 ADD 字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];- 修改数据类型
sql
ALTER TABLE 表名 MODIFY 字段名 新数据类型 (长度);- 修改字段名和字段类型
sql
ALTER TABLE 表名 CHANGE 旧字段名 新字段名 类型 (长度) [ COMMENT 注释 ] [ 约束 ];- 删除字段
sql
ALTER TABLE 表名 DROP 字段名;- 修改表名
sql
ALTER TABLE 表名 RENAME TO 新表名;- 删除表
sql
DROP TABLE [ IF EXISTS ] 表名;- 删除指定表, 并重新创建表
sql
TRUNCATE TABLE 表名;DML
DML英文全称是Data Manipulation Language(数据操作语言),用来对数据库中表的数据记录进行增、删、改操作。
- 给字段添加数据
sql
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...);- 批量添加数据
sql
INSERT INTO 表名 (字段名1, 字段名2, ...) VALUES (值1, 值2, ...), (值1, 值2, ...), (值1, 值2, ...);- 修改数据
sql
UPDATE 表名 SET 字段名1 = 值1 , 字段名2 = 值2 , .... [ WHERE 条件 ] ;- 删除数据
sql
DELETE FROM 表名 [ WHERE 条件 ] ;DQL
DQL英文全称是Data Query Language(数据查询语言),数据查询语言,用来查询数据库中表的记录。

聚合函数
sql
SELECT 聚合函数[字段列表] FROM 表名;| 函数 | 作用 |
|---|---|
| count | 统计数量 |
| max | 最大值 |
| min | 最小值 |
| avg | 平均值 |
| sum | 求和 |
分组查询
sql
SELECT 字段列表 FROM 表名 [ WHERE 条件 ] GROUP BY 分组字段名 [ HAVING 分组后过滤条件 ];where 与 having
执行时机不同:where是分组之前进行过滤,不满足where条件,不参与分组;而having是分组之后对结果进行过滤。
判断条件不同:where不能对聚合函数进行判断,而having可以。
执行顺序: where > 聚合函数 > having
排序查询
sql
SELECT 字段列表 FROM 表名 ORDER BY 字段1 排序方式1 , 字段2 排序方式2;分页查询
sql
SELECT 字段列表 FROM 表名 LIMIT 起始索引, 查询记录数;DCL
DCL英文全称是Data Control Language(数据控制语言),用来管理数据库用户、控制数据库的访问权限。
管理用户
- 查询用户
sql
select * from mysql.user;- 创建用户
sql
CREATE USER '用户名'@'主机名' IDENTIFIED BY '密码';- 修改用户密码
sql
ALTER USER '用户名'@'主机名' IDENTIFIED WITH mysql_native_password BY '新密码' ;- 删除用户
sql
DROP USER '用户名'@'主机名' ;| 权限 | 描述 |
|---|---|
| ALL, ALL PRIVILEGES | 所有权限 |
| SELECT | 查询数据 |
| INSERT | 插入数据 |
| UPDATE | 修改数据 |
| DELETE | 删除数据 |
| ALTER | 修改表 |
| DROP | 删除数据库/表/视图 |
| CREATE | 创建数据库/表 |
- 查询权限
sql
SHOW GRANTS FOR '用户名'@'主机名';- 授予权限
sql
GRANT 权限列表 ON 数据库名.表名 TO '用户名'@'主机名';- 撤销权限
sql
REVOKE 权限列表 ON 数据库名.表名 FROM '用户名'@'主机名';函数
字符串函数
| 函数 | 描述 |
|---|---|
| CONCAT(S1,S2,…Sn) | 字符串拼接,将S1,S2,… Sn拼接成一个字符串 |
| LOWER(str)/UPPER(str) | 将字符串str全部转为小写/大写 |
| LPAD(str,n,pad)/RPAD(str,n,pad) | 左/右填充,用字符串pad对str的左/右边进行填充,达到n个字符串长度 |
| TRIM(str) | 去掉字符串头部和尾部的空格 |
| SUBSTRING(str,start,len) | 返回从字符串str从start位置起的len个长度的字符串 |
- 字符串拼接
sql
select concat('Hello' , ' MySQL');
-- Hello MySQL- 大小写转化
sql
select lower('MySQL');
select upper('Hello');
-- mysql
-- HELLO- 填充
sql
select lpad('01', 5, '-');
select rpad('01', 5, '-');
-- ---01
-- 01---- 去除空格
sql
select trim(' Hello MySQL ');
-- Hello MySQL- 字符串截取
sql
select substring('Hello MySQL',1,4);
-- Hell数值函数
- 取整
sql
select ceil(1.1);
select floor(1.9);
-- 2
-- 1- 取模
sql
select mod(7,4);
-- 3- 获取0-1之间的随机数
sql
select rand();
-- 0.32115931234534- 四舍五入
sql
select round(2.344,2);
select round(2.345,2);
-- 2.34
-- 2.35日期函数
- 当前日期/时间
sql
select curdate();
select curtime();- 当前日期和时间
sql
select now();- 当前年、月、日
sql
select YEAR(now());
select MONTH(now());
select DAY(now());- 增加指定的时间间隔
sql
select date_add(now(), INTERVAL 70 YEAR );- 获取两个日期相差的天数
sql
select datediff('2021-10-01', '2021-12-01');流程函数
| 函数 | 描述 |
|---|---|
| IF(value , t , f) | 如果value为true,则返回t,否则返回 f |
| IFNULL(value1 , value2) | 如果value1不为空,返回value1,否则返回value2 |
| CASE WHEN [ val1 ] THEN [res1] … ELSE [ default ] END | 如果val1为true,返回res1,… 否则返回default默认值 |
| CASE [ expr ] WHEN [ val1 ] THEN [res1] … ELSE [ default ] END | 如果expr的值等于val1,返回 res1,… 否则返回default默认值 |
- if
sql
select if(false, 'Ok', 'Error');- ifnull
sql
select ifnull('Ok','Default');
select ifnull('','Default');
select ifnull(null,'Default');- case when then else end
sql
select
name,
( case workaddress
when '北京' then '一线城市'
when '上海' then '一线城市'
else '二线城市' end )
as '工作地址'
from emp;多表查询
内连接
sql
SELECT 字段列表 FROM 表1 , 表2 WHERE 条件 ... ;
SELECT 字段列表 FROM 表1 [ INNER ] JOIN 表2 ON 连接条件 ... ;外连接
sql
SELECT 字段列表 FROM 表1 LEFT [ OUTER ] JOIN 表2 ON 条件 ... ;
SELECT 字段列表 FROM 表1 RIGHT [ OUTER ] JOIN 表2 ON 条件 ... ;自连接
sql
SELECT 字段列表 FROM 表A 别名A JOIN 表A 别名B ON 条件 ... ;联合查询
sql
SELECT 字段列表 FROM 表A ...
UNION [ ALL ]
SELECT 字段列表 FROM 表B ....;- 对于联合查询的多张表的列数必须保持一致,字段类型也需要保持一致。
- union all 会将全部的数据直接合并在一起,union 会对合并之后的数据去重。
子查询
sql
SELECT * FROM t1 WHERE column1 = ( SELECT column1 FROM t2 );事务
查看 / 设置事务提交方式
sql
SELECT @@autocommit ;
SET @@autocommit = 0 ;
START TRANSACTION 或 BEGIN ;提交事务
sql
COMMIT;回滚事务
sql
ROLLBACK;并发事务问题
赃读:一个事务读到另外一个事务还没有提交的数据,脏读发生在一个事务读取了另一个事务未提交的数据。如果那个事务回滚,读取的数据将是无效的。
不可重复读:一个事务先后读取同一条记录,但两次读取的数据不同,不可重复读发生在一个事务读取了某些数据,然后另一个事务修改或删除了这些数据。当第一个事务再次读取相同的数据时,得到的结果不同。
幻读:一个事务按照条件查询数据时,没有对应的数据行,但是在插入数据时,又发现这行数据已经存在,幻读类似于不可重复读,但它是指当一个事务重新执行一个查询时,返回一组符合查询条件的行,但这组行中包含了因为其他事务插入的新行。
事务隔离级别
读未提交 (Read Uncommitted):最低的隔离级别,允许读取未提交的数据变更,可能会导致脏读、不可重复读和幻读。
读已提交 (Read Committed):保证读取的数据是已经被提交的。这可以避免脏读,但不可重复读和幻读仍然可能发生。
可重复读 (Repeatable Read):保证在同一个事务内的查询可以多次执行而返回相同的结果,即在事务开始后无法看到其他事务对数据所做的修改。这可以防止脏读和不可重复读,但幻读可能发生。
串行化 (Serializable):最高的隔离级别,通过强制事务串行执行,防止脏读、不可重复读和幻读。
查看事务隔离级别
sql
SELECT @@TRANSACTION_ISOLATION;设置事务隔离级别
sql
SET
[ SESSION | GLOBAL ]
TRANSACTION ISOLATION LEVEL
{ READ UNCOMMITTED | READ COMMITTED | REPEATABLE READ | SERIALIZABLE };存储引擎
innodb逻辑存储结构
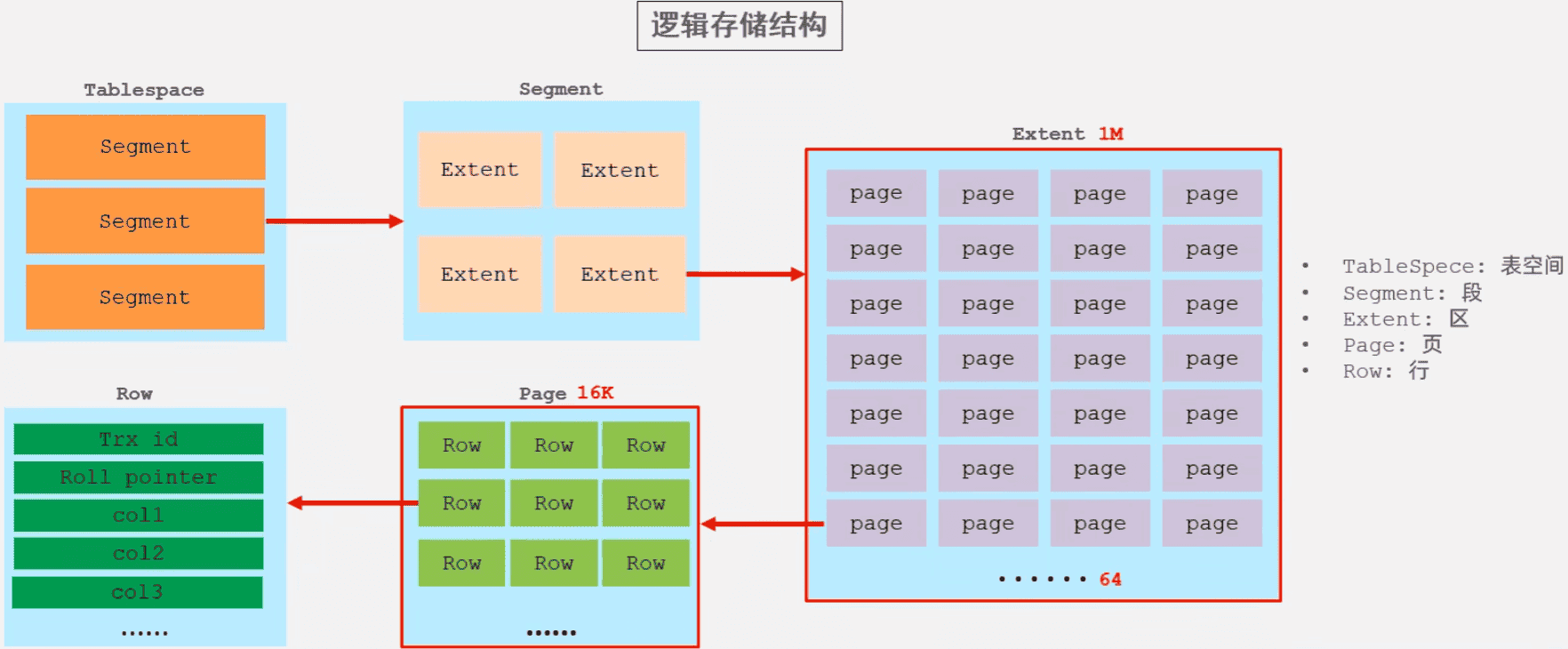
- 表空间 InnoDB存储引擎逻辑结构的最高层,ibd文件其实就是表空间文件,在表空间中可以包含多Segment段。
- 段 表空间是由各个段组成的, 常见的段有数据段、索引段、回滚段等。InnoDB中对于段的管理,都是引擎自身完成,不需要人为对其控制,一个段中包含多个区。
- 区 区是表空间的单元结构,每个区的大小为1M。 默认情况下, InnoDB存储引擎页大小为16K, 即一个区中一共有64个连续的页。
- 页 页是组成区的最小单元,页也是InnoDB 存储引擎磁盘管理的最小单元,每个页的大小默认为 16KB。为了保证页的连续性,InnoDB 存储引擎每次从磁盘申请 4-5 个区。
- 行 InnoDB 存储引擎是面向行的,也就是说数据是按行进行存放的,在每一行中除了定义表时所指定的字段以外,还包含两个隐藏字段。
索引
数据结构可视化: https://www.cs.usfca.edu/~galles/visualization/Algorithms.html
B Tree,B树是一种多叉路衡查找树,相对于二叉树,B树每个节点可以有多个分支,即多叉。一旦节点存储的key数量到达5,就会裂变,中间元素向上分裂。在B树中,非叶子节点和叶子节点都会存放数据。
节点存储:B树的每个节点可以包含多个键和子节点指针。每个节点内部的键和值都是混合存储的,即节点中既存储键也存储数据。
叶子节点:B树的叶子节点并不一定构成一个链表,叶子节点之间没有直接的指针相连。
查询操作:在B树中,查询操作需要沿着树遍历到叶子节点,找到对应的键和值。
数据分布:数据分布在所有的节点中,包括内部节点和叶子节点。

B+Tree
节点存储:B+树的内部节点只存储键,而不存储数据。数据只存储在叶子节点中。
叶子节点:B+树的所有叶子节点形成一个链表,叶子节点之间有指针相连。这样可以方便地进行区间查询和顺序遍历。
查询操作:在B+树中,查询操作最终都落在叶子节点上,因为只有叶子节点存储实际的数据。内部节点只用于导航。
数据分布:所有数据都存储在叶子节点中,内部节点只存储索引键。
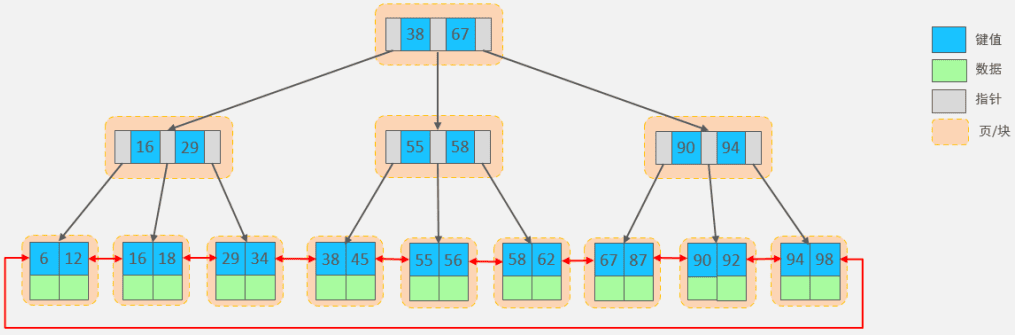
区别:
数据存储位置:
- B树:数据存储在所有节点(内部节点和叶子节点)中。
- B+树:数据仅存储在叶子节点中,内部节点只存储键用于索引。
叶子节点的链表结构:
- B树:叶子节点之间没有额外的链接。
- B+树:叶子节点形成一个链表,便于范围查询和遍历。
查找效率:
- B树:查找可能会在任意一个节点上结束。
- B+树:查找总是在叶子节点结束,叶子节点的链表结构可以提高顺序查找的效率。
空间利用:
- B树:由于数据存储在所有节点中,内部节点可能占用较多空间。
- B+树:内部节点只存储键,因此可能占用较少空间,数据集中在叶子节点中。
B+树相对于B树在查找、插入和删除操作中表现出更高的效率,尤其是在需要进行范围查询和顺序访问的场景中,B+树的叶子节点链表结构提供了显著的优势。而B树的结构更为简单直接,适用于对数据和索引的混合存储需求。
Hash
哈希索引就是采用一定的hash算法,将键值换算成新的hash值,映射到对应的槽位上,然后存储在hash表中。
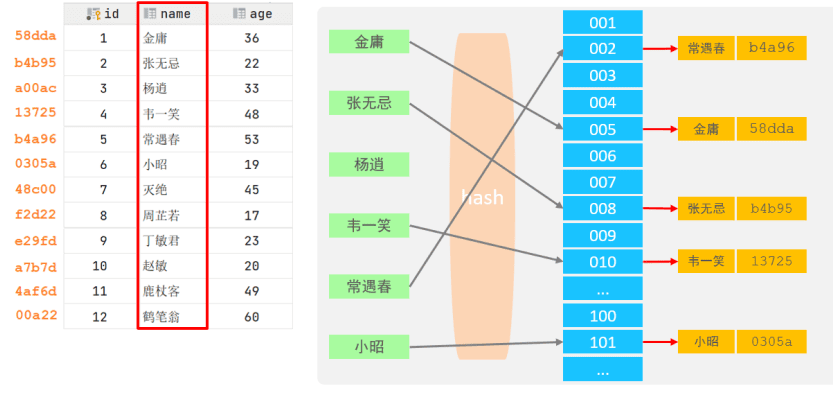
- Hash索引只能用于对等比较(=,in),不支持范围查询(between,>,< ,…)
- 无法利用索引完成排序操作。
- 查询效率高,通常(不存在hash冲突的情况)只需要一次检索就可以了,效率通常要高于B+tree索引。
聚集索引&二级索引
| 分类 | 含义 | 特点 |
|---|---|---|
| 将数据存储与索引放到了一块,索引结构的叶子 节点保存了行数据 | 必须有, 而且只有一个 | |
| 二级索引(Secondary Index) | 将数据与索引分开存储,索引结构的叶子节点关 联的是对应的主键 | 可以存在多个 |
- 如果存在主键,主键索引就是聚集索引。
- 如果不存在主键,将使用第一个唯一(UNIQUE)索引作为聚集索引。
- 如果表没有主键,或没有合适的唯一索引,则InnoDB会自动生成一个rowid作为隐藏的聚集索引。
聚集索引和二级索引的具体结构
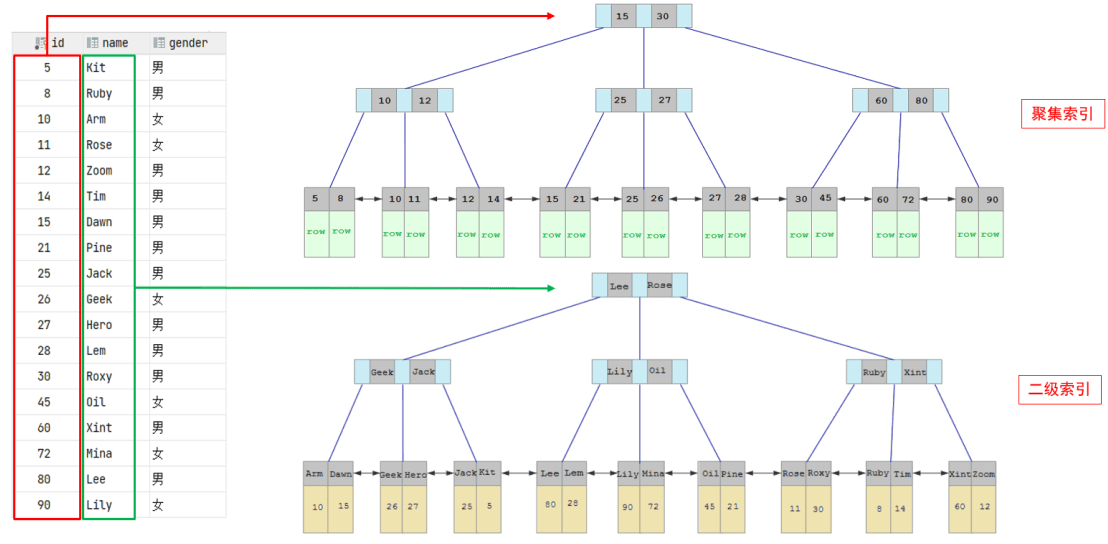
二级索引回表查询

索引语法
创建索引
sql
CREATE [ UNIQUE | FULLTEXT ] INDEX index_name ON table_name (index_col_name,... );查看索引
sql
SHOW INDEX FROM table_name;删除索引
sql
DROP INDEX index_name ON table_name;SQL性能优化
SQL执行频率
MySQL 客户端连接成功后,通过 show [session|global] status 命令可以提供服务器状态信息。可以查看当前数据库的INSERT、UPDATE、DELETE、SELECT的访问频次:
sql
SHOW GLOBAL STATUS LIKE 'Com_______';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| Com_binlog | 0 |
| Com_commit | 0 |
| Com_delete | 20 |
| Com_import | 0 |
| Com_insert | 53 |
| Com_repair | 0 |
| Com_revoke | 0 |
| Com_select | 29 |
| Com_signal | 0 |
| Com_update | 7 |
| Com_xa_end | 0 |
+---------------+-------+慢查询日志
慢查询日志记录了所有执行时间超过指定参数(long_query_time,单位:秒,默认10秒)的所有SQL语句的日志。修改MySQL的配置文件 /etc/my.cnf 开启日志查询
text
# 开启MySQL慢日志查询开关
slow_query_log=1
# 设置慢日志的时间为2秒,SQL语句执行时间超过2秒,就会视为慢查询,记录慢查询日志
long_query_time=2重启mysql
shell
sudo systemctl restart mysqld执行查询sql,查询慢日志信息 /var/lib/mysql/localhost-slow.log
profile
sql
-- 查询是否支持profile
SELECT @@have_profiling;
-- 开启profile
SET profiling = 1;
-- 查看每一条SQL的耗时基本情况
show profiles;
-- 查看指定query_id的SQL语句各个阶段的耗时情况
show profile for query query_id;
-- 查看指定query_id的SQL语句CPU的使用情况
show profile cpu for query query_id;explain
EXPLAIN 或者 DESC 命令获取 MySQL 如何执行 SELECT 语句的信息,包括在 SELECT 语句执行过程中表如何连接和连接的顺序。
sql
-- 直接在select语句之前加上关键字 explain / desc
EXPLAIN SELECT 字段列表 FROM 表名 WHERE 条件 ;text
mysql> explain select * from tb_user where id = 1;
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| id | select_type | table | partitions | type | possible_keys | key | key_len | ref | rows | filtered | Extra |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
| 1 | SIMPLE | tb_user | NULL | const | PRIMARY | PRIMARY | 4 | const | 1 | 100.00 | NULL |
+----+-------------+---------+------------+-------+---------------+---------+---------+-------+------+----------+-------+
1 row in set, 1 warning (0.00 sec)| 字段 | 含义 |
|---|---|
| id | select查询的序列号,表示查询中执行select子句或者是操作表的顺序 (id相同,执行顺序从上到下;id不同,值越大,越先执行)。 |
| select_type | SELECT 的类型,常见的取值有 SIMPLE(简单表,即不使用表连接 或者子查询)、PRIMARY(主查询,即外层的查询)、 UNION(UNION 中的第二个或者后面的查询语句)、 SUBQUERY(SELECT/WHERE之后包含了子查询)等。 |
| type | 表示连接类型,性能由好到差的连接类型为NULL、system、const、 eq_ref、ref、range、 index、all 。 |
| possible_key | 显示可能应用在这张表上的索引,一个或多个。 |
| key | 实际使用的索引,如果为NULL,则没有使用索引。 |
| key_len | 表示索引中使用的字节数, 该值为索引字段最大可能长度,并非实际使用长 度,在不损失精确性的前提下, 长度越短越好 。 |
| rows | MySQL认为必须要执行查询的行数,在innodb引擎的表中,是一个估计值, 可能并不总是准确的。 |
| filtered | 表示返回结果的行数占需读取行数的百分比, filtered 的值越大越好。 |
最左前缀法则
在MySQL中,最左前缀法则(Leftmost Prefix Rule)与索引的使用和优化密切相关。这条法则规定了如何有效地利用多列索引来优化查询。理解和应用这一法则可以显著提高查询性能。最左前缀法则指出,MySQL 在使用多列索引时,会从索引的最左列开始,依次利用索引中的列进行匹配。只有满足最左前缀的查询条件才能有效使用索引。如果查询条件中跳过了索引中的某一列,则索引在该列之后的部分将无法被有效利用。
假设有一个包含三列的多列索引:
sql
CREATE INDEX idx_example ON table_name (column1, column2, column3);有效利用索引的查询:
完全匹配最左前缀:
sqlSELECT * FROM table_name WHERE column1 = 'value1';匹配最左前缀的前两列:
sqlSELECT * FROM table_name WHERE column1 = 'value1' AND column2 = 'value2';匹配最左前缀的前三列:
sqlSELECT * FROM table_name WHERE column1 = 'value1' AND column2 = 'value2' AND column3 = 'value3';
无法有效利用索引的查询:
跳过了最左前缀的第一列:
sqlSELECT * FROM table_name WHERE column2 = 'value2';跳过了中间的列:
sqlSELECT * FROM table_name WHERE column1 = 'value1' AND column3 = 'value3';
锁
参考博文: