CAS 的全称是 Compare-And-Swap,是 CPU 并发原语
- CAS 并发原语体现在 Java 语言中就是
sun.misc.Unsafe类的各个方法,调用 UnSafe 类中的 CAS 方法,JVM 会实现出 CAS 汇编指令,这是一种完全依赖于硬件的功能,实现了原子操作 - CAS 是一种系统原语,原语属于操作系统范畴,是由若干条指令组成 ,用于完成某个功能的一个过程,并且原语的执行必须是连续的,执行过程中不允许被中断,所以 CAS 是一条 CPU 的原子指令,不会造成数据不一致的问题,是线程安全的
底层原理:CAS 的底层是 lock cmpxchg 指令(X86 架构),在单核和多核 CPU 下都能够保证比较交换的原子性
- 程序是在单核处理器上运行,会省略 lock 前缀,单处理器自身会维护处理器内的顺序一致性,不需要 lock 前缀的内存屏障效果
- 程序是在多核处理器上运行,会为 cmpxchg 指令加上 lock 前缀。当某个核执行到带 lock 的指令时,CPU 会执行总线锁定或缓存锁定,将修改的变量写入到主存,这个过程不会被线程的调度机制所打断,保证了多个线程对内存操作的原子性
作用:比较当前工作内存中的值和主物理内存中的值,如果相同则执行规定操作,否则继续比较直到主内存和工作内存的值一致为止
CAS 特点:
- CAS 体现的是无锁并发、无阻塞并发,线程不会陷入阻塞,线程不需要频繁切换状态(上下文切换,系统调用)
- CAS 是基于乐观锁的思想
CAS 缺点:
- 执行的是循环操作,如果比较不成功一直在循环,最差的情况某个线程一直取到的值和预期值都不一样,就会无限循环导致饥饿,使用 CAS 线程数不要超过 CPU 的核心数,采用分段 CAS 和自动迁移机制
- 只能保证一个共享变量的原子操作
- 对于一个共享变量执行操作时,可以通过循环 CAS 的方式来保证原子操作
- 对于多个共享变量操作时,循环 CAS 就无法保证操作的原子性,这个时候只能用锁来保证原子性
- ABA 问题
Atomic
常见原子类:AtomicInteger、AtomicBoolean、AtomicLong
构造方法:
public AtomicInteger():初始化一个默认值为 0 的原子型 Integerpublic AtomicInteger(int initialValue):初始化一个指定值的原子型 Integer
常用API:
| 方法 | 作用 |
|---|---|
| public final int get() | 获取 AtomicInteger 的值 |
| public final int getAndIncrement() | 以原子方式将当前值加 1,返回的是自增前的值 |
| public final int incrementAndGet() | 以原子方式将当前值加 1,返回的是自增后的值 |
| public final int getAndSet(int value) | 以原子方式设置为 newValue 的值,返回旧值 |
| public final int addAndGet(int data) | 以原子方式将输入的数值与实例中的值相加并返回 实例:AtomicInteger 里的 value |
AtomicInteger
getAndSet 方法:
1
2
3
4
5
6
7public final int getAndSet(int newValue) {
/**
* this: 当前对象
* valueOffset: 内存偏移量,内存地址
*/
return unsafe.getAndSetInt(this, valueOffset, newValue);
}valueOffset:偏移量表示该变量值相对于当前对象地址的偏移,Unsafe 就是根据内存偏移地址获取数据
1
2
3
4valueOffset = unsafe.objectFieldOffset
(AtomicInteger.class.getDeclaredField("value"));
//调用本地方法 -->
public native long objectFieldOffset(Field var1);unsafe 类:
1
2
3
4
5
6
7
8
9
10// val1: AtomicInteger对象本身,var2: 该对象值得引用地址,var4: 需要变动的数
public final int getAndSetInt(Object var1, long var2, int var4) {
int var5;
do {
// var5: 用 var1 和 var2 找到的内存中的真实值
var5 = this.getIntVolatile(var1, var2);
} while(!this.compareAndSwapInt(var1, var2, var5, var4)); // [!code focus]
return var5;
}var5:从主内存中拷贝到工作内存中的值(每次都要从主内存拿到最新的值到本地内存),然后执行
compareAndSwapInt()再和主内存的值进行比较,假设方法返回 false,那么就一直执行 while 方法,直到期望的值和真实值一样,修改数据变量 value 用 volatile 修饰,保证了多线程之间的内存可见性,避免线程从工作缓存中获取失效的变量
1
private volatile int value
CAS 必须借助 volatile 才能读取到共享变量的最新值来实现比较并交换的效果
getAndUpdate方法:
1
2
3
4
5
6
7
8public final int getAndUpdate(IntUnaryOperator updateFunction) {
int prev, next;
do {
prev = get(); //当前值,cas的期望值
next = updateFunction.applyAsInt(prev);//期望值更新到该值
} while (!compareAndSet(prev, next));//自旋
return prev;
}compareAndSet:
1
2
3
4
5
6
7
8
9public final boolean compareAndSet(int expect, int update) {
/**
* this: 当前对象
* valueOffset: 内存偏移量,内存地址
* expect: 期望的值
* update: 更新的值
*/
return unsafe.compareAndSwapInt(this, valueOffset, expect, update);
}
原子引用
对 Object 进行原子操作,提供一种读和写都是原子性的对象引用变量
原子引用类:AtomicReference、AtomicStampedReference、AtomicMarkableReference
AtomicReference
- 构造方法:
AtomicReference<T> atomicReference = new AtomicReference<T>() - 常用 API:
public final boolean compareAndSet(V expectedValue, V newValue):CAS 操作public final void set(V newValue):将值设置为 newValuepublic final V get():返回当前值
1 | public class AtomicReferenceDemo { |
原子数组
原子数组类:AtomicIntegerArray、AtomicLongArray、AtomicReferenceArray
AtomicIntegerArray 类方法:
1 | /** |
原子更新器
利用字段更新器,可以针对对象的某个域(Field)进行原子操作,只能配合 volatile 修饰的字段使用,否则会出现异常
IllegalArgumentException: Must be volatile type
原子更新器类:AtomicReferenceFieldUpdater、AtomicIntegerFieldUpdater、AtomicLongFieldUpdater
常用 API:
static <U> AtomicIntegerFieldUpdater<U> newUpdater(Class<U> c, String fieldName):构造方法abstract boolean compareAndSet(T obj, int expect, int update):CAS
1 | public class UpdateDemo { |
原子累加器
原子累加器类:LongAdder、DoubleAdder、LongAccumulator、DoubleAccumulator
LongAdder 和 LongAccumulator 区别:
相同点:
- LongAddr 与 LongAccumulator 类都是使用非阻塞算法 CAS 实现的
- LongAddr 类是 LongAccumulator 类的一个特例,LongAccumulator 提供了更强大的功能,可以自定义累加规则,当accumulatorFunction 为 null 时就等价于 LongAddr
不同点:
- 调用 casBase 时,LongAccumulator 使用 function.applyAsLong(b = base, x) 来计算,LongAddr 使用 casBase(b = base, b + x)
- LongAccumulator 类功能更加强大,构造方法参数中
- accumulatorFunction 是一个双目运算器接口,可以指定累加规则,比如累加或者相乘,其根据输入的两个参数返回一个计算值,LongAdder 内置累加规则
- identity 则是 LongAccumulator 累加器的初始值,LongAccumulator 可以为累加器提供非0的初始值,而 LongAdder 只能提供默认的 0
Adder
LongAdder 是 Java8 提供的类,跟 AtomicLong 有相同的效果,但对 CAS 机制进行了优化,尝试使用分段 CAS 以及自动分段迁移的方式来大幅度提升多线程高并发执行 CAS 操作的性能,CAS 底层实现是在一个循环中不断地尝试修改目标值,直到修改成功。如果竞争不激烈修改成功率很高,否则失败率很高,失败后这些重复的原子性操作会耗费性能(导致大量线程空循环,自旋转)
优化核心思想:数据分离,将 AtomicLong 的单点的更新压力分担到各个节点,空间换时间,在低并发的时候直接更新,可以保障和 AtomicLong 的性能基本一致,而在高并发的时候通过分散减少竞争,提高了性能
分段 CAS 机制:
- 在发生竞争时,创建 Cell 数组用于将不同线程的操作离散(通过 hash 等算法映射)到不同的节点上
- 设置多个累加单元(会根据需要扩容,最大为 CPU 核数),Therad-0 累加 Cell[0],而 Thread-1 累加 Cell[1] 等,最后将结果汇总
- 在累加时操作的不同的 Cell 变量,因此减少了 CAS 重试失败,从而提高性能
自动分段迁移机制:某个 Cell 的 value 执行 CAS 失败,就会自动寻找另一个 Cell 分段内的 value 值进行 CAS 操作
伪共享
Cell 为累加单元:数组访问索引是通过 Thread 里的 threadLocalRandomProbe 域取模实现的,这个域是 ThreadLocalRandom 更新的
1 | // Striped64.Cell |
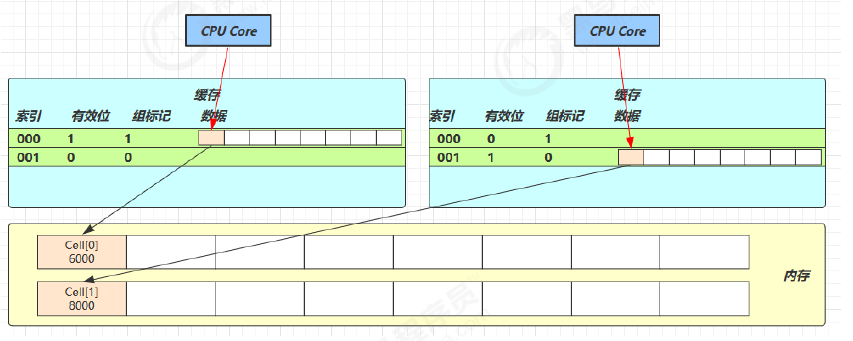
Cell 是数组形式,在内存中是连续存储的,64 位系统中,一个 Cell 为 24 字节(16 字节的对象头和 8 字节的 value),每一个 cache line 为 64 字节,因此缓存行可以存下 2 个的 Cell 对象,当 Core-0 要修改 Cell[0]、Core-1 要修改 Cell[1],无论谁修改成功都会导致当前缓存行失效,从而导致对方的数据失效,需要重新去主存获取,影响效率
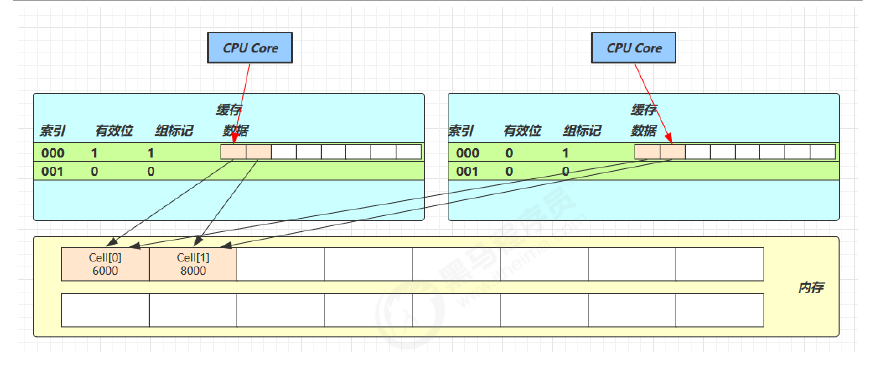 @sun.misc.Contended:防止缓存行伪共享,在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,使用 2 倍于大多数硬件缓存行让 CPU 将对象预读至缓存时占用不同的缓存行,这样就不会造成对方缓存行的失效
@sun.misc.Contended:防止缓存行伪共享,在使用此注解的对象或字段的前后各增加 128 字节大小的 padding,使用 2 倍于大多数硬件缓存行让 CPU 将对象预读至缓存时占用不同的缓存行,这样就不会造成对方缓存行的失效
源码解析
Striped64 类成员属性:
1 | // 表示当前计算机CPU数量 |
工作流程:
- cells 占用内存是相对比较大的,是惰性加载的,在无竞争或者其他线程正在初始化 cells 数组的情况下,直接更新 base 域
- 在第一次发生竞争时(casBase 失败)会创建一个大小为 2 的 cells 数组,将当前累加的值包装为 Cell 对象,放入映射的槽位上
- 分段累加的过程中,如果当前线程对应的 cells 槽位为空,就会新建 Cell 填充,如果出现竞争,就会重新计算线程对应的槽位,继续自旋尝试修改
- 分段迁移后还出现竞争就会扩容 cells 数组长度为原来的两倍,然后 rehash,数组长度总是 2 的 n 次幂,默认最大为 CPU 核数,但是可以超过,如果核数是 6 核,数组最长是 8
方法分析:
LongAdder#add:累加方法
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24public void add(long x) {
// as 为累加单元数组的引用,b 为基础值,v 表示期望值
// m 表示 cells 数组的长度 - 1,a 表示当前线程命中的 cell 单元格
Cell[] as; long b, v; int m; Cell a;
// cells 不为空说明 cells 已经被初始化,线程发生了竞争,去更新对应的 cell 槽位
// 进入 || 后的逻辑去更新 base 域,更新失败表示发生竞争进入条件
if ((as = cells) != null || !casBase(b = base, b + x)) {
// uncontended 为 true 表示 cell 没有竞争
boolean uncontended = true;
// 条件一: true 说明 cells 未初始化,多线程写 base 发生竞争需要进行初始化 cells 数组
// fasle 说明 cells 已经初始化,进行下一个条件寻找自己的 cell 去累加
// 条件二: getProbe() 获取 hash 值,& m 的逻辑和 HashMap 的逻辑相同,保证散列的均匀性
// true 说明当前线程对应下标的 cell 为空,需要创建 cell
// false 说明当前线程对应的 cell 不为空,进行下一个条件【将 x 值累加到对应的 cell 中】
// 条件三: 有取反符号,false 说明 cas 成功,直接返回,true 说明失败,当前线程对应的 cell 有竞争
if (as == null || (m = as.length - 1) < 0 ||
(a = as[getProbe() & m]) == null ||
!(uncontended = a.cas(v = a.value, v + x)))
longAccumulate(x, null, uncontended);
// 【uncontended 在对应的 cell 上累加失败的时候才为 false,其余情况均为 true】
}
}Striped64#longAccumulate:cell 数组创建
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
100
101
102
103
104
105
106
107
108
109
110
111
112
113// x null false | true
final void longAccumulate(long x, LongBinaryOperator fn, boolean wasUncontended) {
int h;
// 当前线程还没有对应的 cell, 需要随机生成一个 hash 值用来将当前线程绑定到 cell
if ((h = getProbe()) == 0) {
// 初始化 probe,获取 hash 值
ThreadLocalRandom.current();
h = getProbe();
// 默认情况下 当前线程肯定是写入到了 cells[0] 位置,不把它当做一次真正的竞争
wasUncontended = true;
}
// 表示【扩容意向】,false 一定不会扩容,true 可能会扩容
boolean collide = false;
//自旋
for (;;) {
// as 表示cells引用,a 表示当前线程命中的 cell,n 表示 cells 数组长度,v 表示 期望值
Cell[] as; Cell a; int n; long v;
// 【CASE1】: 表示 cells 已经初始化了,当前线程应该将数据写入到对应的 cell 中
if ((as = cells) != null && (n = as.length) > 0) {
// CASE1.1: true 表示当前线程对应的索引下标的 Cell 为 null,需要创建 new Cell
if ((a = as[(n - 1) & h]) == null) {
// 判断 cellsBusy 是否被锁
if (cellsBusy == 0) {
// 创建 cell, 初始累加值为 x
Cell r = new Cell(x);
// 加锁
if (cellsBusy == 0 && casCellsBusy()) {
// 创建成功标记,进入【创建 cell 逻辑】
boolean created = false;
try {
Cell[] rs; int m, j;
// 把当前 cells 数组赋值给 rs,并且不为 null
if ((rs = cells) != null &&
(m = rs.length) > 0 &&
// 再次判断防止其它线程初始化过该位置,当前线程再次初始化该位置会造成数据丢失
// 因为这里是线程安全的判断,进行的逻辑不会被其他线程影响
rs[j = (m - 1) & h] == null) {
// 把新创建的 cell 填充至当前位置
rs[j] = r;
created = true; // 表示创建完成
}
} finally {
cellsBusy = 0; // 解锁
}
if (created) // true 表示创建完成,可以推出循环了
break;
continue;
}
}
collide = false;
}
// CASE1.2: 条件成立说明线程对应的 cell 有竞争, 改变线程对应的 cell 来重试 cas
else if (!wasUncontended)
wasUncontended = true;
// CASE 1.3: 当前线程 rehash 过,如果新命中的 cell 不为空,就尝试累加,false 说明新命中也有竞争
else if (a.cas(v = a.value, ((fn == null) ? v + x : fn.applyAsLong(v, x))))
break;
// CASE 1.4: cells 长度已经超过了最大长度 CPU 内核的数量或者已经扩容
else if (n >= NCPU || cells != as)
collide = false; // 扩容意向改为false,【表示不能扩容了】
// CASE 1.5: 更改扩容意向,如果 n >= NCPU,这里就永远不会执行到,case1.4 永远先于 1.5 执行
else if (!collide)
collide = true;
// CASE 1.6: 【扩容逻辑】,进行加锁
else if (cellsBusy == 0 && casCellsBusy()) {
try {
// 线程安全的检查,防止期间被其他线程扩容了
if (cells == as) {
// 扩容为以前的 2 倍
Cell[] rs = new Cell[n << 1];
// 遍历移动值
for (int i = 0; i < n; ++i)
rs[i] = as[i];
// 把扩容后的引用给 cells
cells = rs;
}
} finally {
cellsBusy = 0; // 解锁
}
collide = false; // 扩容意向改为 false,表示不扩容了
continue;
}
// 重置当前线程 Hash 值,这就是【分段迁移机制】
h = advanceProbe(h);
}
// 【CASE2】: 运行到这说明 cells 还未初始化,as 为null
// 判断是否没有加锁,没有加锁就用 CAS 加锁
// 条件二判断是否其它线程在当前线程给 as 赋值之后修改了 cells,这里不是线程安全的判断
else if (cellsBusy == 0 && cells == as && casCellsBusy()) {
// 初始化标志,开始 【初始化 cells 数组】
boolean init = false;
try {
// 再次判断 cells == as 防止其它线程已经提前初始化了,当前线程再次初始化导致丢失数据
// 因为这里是【线程安全的,重新检查,经典 DCL】
if (cells == as) {
Cell[] rs = new Cell[2]; // 初始化数组大小为2
rs[h & 1] = new Cell(x); // 填充线程对应的cell
cells = rs;
init = true; // 初始化成功,标记置为 true
}
} finally {
cellsBusy = 0; // 解锁啊
}
if (init)
break; // 初始化成功直接跳出自旋
}
// 【CASE3】: 运行到这说明其他线程在初始化 cells,当前线程将值累加到 base,累加成功直接结束自旋
else if (casBase(v = base, ((fn == null) ? v + x :
fn.applyAsLong(v, x))))
break;
}
}sum:获取最终结果通过 sum 整合,保证最终一致性,不保证强一致性
1
2
3
4
5
6
7
8
9
10
11
12public long sum() {
Cell[] as = cells; Cell a;
long sum = base;
if (as != null) {
// 遍历 累加
for (int i = 0; i < as.length; ++i) {
if ((a = as[i]) != null)
sum += a.value;
}
}
return sum;
}
ABA
当进行获取主内存值时,该内存值在写入主内存时已经被修改了 N 次,但是最终又改成原来的值,其他线程先把 A 改成 B 又改回 A,主线程仅能判断出共享变量的值与最初值 A 是否相同,不能感知到这种从 A 改为 B 又 改回 A 的情况,这时 CAS 虽然成功,但是过程存在问题
- 构造方法:
public AtomicStampedReference(V initialRef, int initialStamp):初始值和初始版本号
- 常用API:
public boolean compareAndSet(V expectedReference, V newReference, int expectedStamp, int newStamp):期望引用和期望版本号都一致才进行 CAS 修改数据public void set(V newReference, int newStamp):设置值和版本号public V getReference():返回引用的值public int getStamp():返回当前版本号
1 | public static void main(String[] args) { |
Unsafe
Unsafe 是 CAS 的核心类,由于 Java 无法直接访问底层系统,需要通过本地(Native)方法来访问,Unsafe 类存在 sun.misc 包,其中所有方法都是 native 修饰的,都是直接调用操作系统底层资源执行相应的任务,基于该类可以直接操作特定的内存数据,其内部方法操作类似 C 的指针
示例:
1 | public static void main(String[] args) { |
final
1 | public class TestFinal { |
字节码:
1 | 0: aload_0 |
final 变量的赋值通过 putfield 指令来完成,在这条指令之后也会加入写屏障,保证在其它线程读到它的值时不会出现为 0 的情况
其他线程访问 final 修饰的变量
- 复制一份放入栈中直接访问,效率高
- 大于 short 最大值会将其复制到类的常量池,访问时从常量池获取
不可变
一个对象不能够修改其内部状态(属性)不可变对象线程安全的,不存在并发修改和可见性问题,是另一种避免竞争的方式
String 类:
1 | public final class String |
类用 final 修饰保证了该类中的方法不能被覆盖,防止子类无意间破坏不可变性
无写入方法(set)确保外部不能对内部属性进行修改
属性用 final 修饰保证了该属性是只读的,不能修改
更改 String 类数据时,会构造新字符串对象,生成新的 char[] value,通过**创建副本对象来避免共享的方式称之为保护性拷贝